以下のようなテーブルがある。
id,item_code,reg_date
1,00A,2014-04-01
2,00B,2014-04-02
3,00C,2014-04-03
4,00A,2014-04-04
5,00B,2014-04-05
6,00A,2014-04-06
ここから、重複を省いて結果を得たい時は DISTINCT を使う。
SELECT DISTINCT `item_code` FROM `テーブル名` ;
00A
00B
00C
しかし「重複しているのは何か」を知りたい時がある。
その場合、以下で対応可能。
SELECT * FORM `テーブル名` GROUP BY `item_code` HAVING COUNT(*) > 1 ;
`item_code`でGROUP化し、その上で件数が1より多い、とすればよい。
1,00A,2014-04-01
2,00B,2014-04-02
但し、GROUP BYを使用しているため、重複している1件は取り出せるが、他は取り出せない。
00Aは3件重複、00Bは2件重複しているが、表示されるのは1件しかなく、その1件はそのうちどれかは未確定である。
関連:MySQLに於けるGROUP BYでのミス(集約キー以外を書いてしまう)
重複しているレコード全てを取り出すには、
SELECT * FORM `テーブル名` WHERE `item_code` IN (SELECT `item_code` FROM `テーブル名` GROUP BY `item_code` HAVING COUNT(*) > 1) ;
とする。
サブクエリは上のSQL文とほぼ同じで、全体からitem_codeが「重複した`item_code`」と同じものを取り出すことで、実現している。
INはORの省略形、との理解で止まりがちだが、条件に合うものを取り出すには、INは非常に適している。
では、ここで例題。
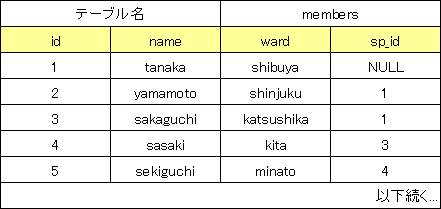
`sp_id`は上司のidを示す。
<部下のいる人のid,name,wardを抽出セヨ>
↓
回答:
SELECT `id`,`name`,`ward` FROM `members` WHERE `id` IN (SELECT `sp_id` FROM `members`) ;

オライリージャパン
売り上げランキング: 12,496
